
Week 41 - Speech to Flashcards

This week I created a workflow to transcribe new words from my Spanish conversation classes into flashcards.

Tool I used:
Baselang - for Spanish conversation class
Backtrack - to record system audio
Whisper.cpp - to transcribe audio locally
ChatGPT - to iterate on python scripts to extract unique words from transcript
MarianMT transformer - to generate English translations of Spanish words
Google sheets - to store my aggregate list of word pairs
Flippity - to generate flashcards
Context
I recently read Ultralearning by Scott H Young, and it inspired me to be more intentional and disciplined about my learning processes. I’ve been learning Spanish for the last 6 months, but at many points it has felt unfocused, which in turn has made it hard to stay motivated.

There are 9 principles in the book - one of them is drill. I have been having regular Spanish conversations, but I haven’t been drilling my weak points: vocab and grammar. Oftentimes I would have a conversation class and learn some new words or concepts, but I’m not a fan of taking notes while chatting, so I wouldn’t take good notes and I’d miss the opportunity to review what I’ve learned in a systematic way.
I wanted to create some way to automate that - so I decided to try using the newly amazing Whisper speech to text model and a few processing steps to generate custom flashcards for each lesson.
Process
I use Baselang to have unlimited flexible Spanish conversation classes, it works well for my schedule, and I’ve found a few teachers I enjoy chatting to, usually for an hour at a time. They recently swapped to requiring Zoom for calls, which I’m not a fan of as they have dodgy clauses in their TOS meaning they own all audio + video from your meetings, and a history of security and privacy issues. Remember.. everything you do online can and probably is being saved somewhere and will soon be efficiently searchable using LLMs. Even Baselang says they sometimes record their classes.
I’m using Backtrack to continuously record the last few hours of my screen and system audio, so it’s easy to capture the audio from a meeting after it’s happened (and yes I ask my teacher if they are ok with it.) They have a transcription option if you upload your file to the cloud, but I’d rather keep it only on my machine, so instead I download the audio directly.

I played around with a few options for transcription, I tried Whishper but had trouble with the docker container setup, instead I found a C++ port of Whisper that worked perfectly via the command line. I followed a guide and used the large model which was very accurate on my Spanish language audio.
Once I had my audio as a text file, I put together a few python scripts (thanks ChatGPT) to parse and count the unique words, add a timestamp, split them into verbs and non-verbs, convert verbs to infinitive form, and generate aggregate files and a new words files. This way I’m keeping a running tally of the words I’ve used as well as lists of new words for each conversation.
I also ran it through a translation model to generate the English word pairs and add those to the files too - I need those for the flashcards.

Currently I use Anki for high quality flashcards with cloze insertions generated by other people. My flashcards aren’t yet that well designed, and to get in the Anki format would take a few extra steps. I wanted to make something very lightweight, so I found Flippity, which simply takes a Google Sheets input as autogenerates flashcards based on the columns.
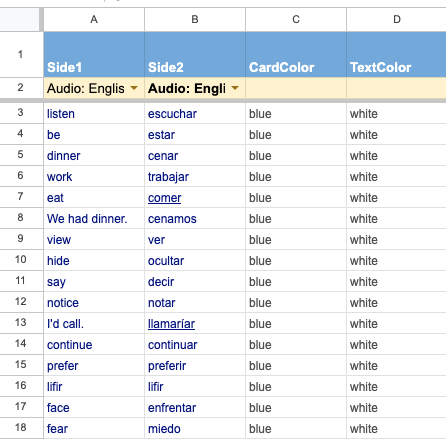
Last step is to copy in the aggregate output into a Google Sheet, then I’m ready to start practicing in Flippity.


There’s still some errors in the word extraction, cleaning, and translation, leading to weirdly conjugated verbs and translations, but its a working prototype!
Learnings
It’s interesting to observe as I do this that a lot of the middle steps will very soon be replaced/abstracted away entirely by a multi-modal LLM. Here is the current workflow:

For several of the steps in the middle I used ChatGPT to write me some or all of the code involved. It’s not a big jump to imagine this will be the next iteration of this:

Next steps
Try to consolidate some of the steps and automate it further
Rebuild it using an LLM to do a lot of the intermediate steps without writing the code myself
Build a frontend and host this on the web for other people to use